
Count me among those who are alarmed about the implications of "AI," such as it is. But I am not among those who worry about machines taking over. I see no signs of intelligence—either from the large language models being hyped right now, or from those doing the hyping. My concern around this technology is more mundane than apocalypse, but more profound than simple economic impact.
I'm terrified we're about to lose the war for truth.
TL;DR: The ability to generate massive amounts of language will be exploited for profit and weaponized to disseminate misinformation against a public that will naively consume this language because it is convenient. Over time, what is true will become indistinguishable from what is hallucinated.
A Unique Hacking Vector
My job is to highlight threats to information security. Normally that takes the shape of vulnerabilities in software or system configurations that can be exploited to compromise the confidentiality, integrity, or availability of stored data.
But before I did this, I taught computer science. Before that, I taught English. Put simply, I have spent my professional life using myriad languages to convey knowledge and intention to others. So have you, I suspect, but maybe you weren't as big a dork about the idea. Me? I've always been fascinated by the ability for us to transmit, however imperfectly, the lightning from one mind to another through language.
I'm not sure humans have a lock on communicating ideas and intention, but we sure do a lot of it. Language in its many forms is core to the human experience. It makes us unimaginably powerful, and dizzyingly vulnerable.
This is the vulnerability we need to talk about now. You are about to get hacked in a way you've never seen before. Maybe you already have been; maybe we all have been. The integrity of our knowledge is in mortal peril.
When you read, listen to, or watch nonfiction, with few exceptions, you have an expectation of the material* being true. At least, you have an expectation that the creator has done their best to present facts in good faith. That's a fair definition of "nonfiction," as far as I can figure. It's important to note here that the "truth" is contingent upon intention. It matters that the people who made the material you're consuming were not trying to deceive you. Their intent is to inform. It is that intent, along with a history of some degree of accuracy, that brings you to their work.
What is the intent of text generated by a large language model (LLM)? Is it attempting to inform? Deceive? Does it have ulterior motives?
Some thinkers have written in horror that we "can't know" the intentions of AI, or that they align with ours. This "alignment problem" has launched countless papers, thinkpieces, podcasts, and one very-well-publicized letter from futurists, oligarchs, and other people who command large audiences at places like Davos, Aspen, and SXSW.
First of all, let's get some terms straight here. The alignment problem, such as it is, concerns Artificial General Intelligence, or AGI, which refers to an artificial intelligence capable of cognitive tasks including reasoning and remembering across multiple domains of knowledge.
I want you to internalize this: There is no such thing as AGI in 2023. Even the most concerned writers and researchers on this topic place likely dates for the emergence of anything like AGI in the 2050s to 2060s. The out-of-control computer is a distraction from the immediate dangers posed by the rapid adoption of large language models.
Large language models do not reason. Their "training" concerns the statistical analysis of massive amounts of text to determine likely correct textual responses based on a given input. This is a simplification, but the basic gist is there: text is ingested, "tokenized" to identify important terms and positions, and based on many rounds of training, the model is eventually "fitted," meaning it reliably produces output that makes sense given the input.
That this methodology produces output as "human" as it does is truly phenomenal. I am in legitimate awe of what has been created. Remember that awe is equal parts wonder and fear.
So back to the question of intent. What meaning lies behind the text generated by LLMs?
Answer: none beyond what you bring to it. The model itself is incapable of intent or meaning. It is not moral or immoral; it is unaware—incapable of awareness—of morality in any useful sense.
We may need some metaphors here.
* I'm going to be avoiding the word "content" for reasons I hope become clear.
A New Chinese Room for LLMs
You can't get too far into philosophical conversations about the nature of Artificial Intelligence without encountering John Searle's 1980 thought experiment known as the "Chinese Room." In it, Searle describes the following scenario: a locked room inside of which is a person and a computer programmed to respond to messages written in Chinese. Messages written in Chinese are slipped under the door to this room, and the person uses the computer to compose a response, which is slipped back under the door.
People on the other side have the impression that the person inside the room "knows Chinese," but of course they are simply repeating what they are told to say by the computer. The thesis here is that passing for human (e.g. the Turing Test) is a terrible heuristic for "intelligence," such as it is.
But this thought experiment needs a little updating to properly capture what's going on with LLMs like ChatGPT. Lemme give it a shot.
This time, we're back in a locked room. Well, maybe more like a locked library—filled with millions of books written in Chinese. The chamber also has the following:
- Infinite sheets of paper
- A pair of scissors
- Infinite glue sticks
- A very scared and confused person
Once again, messages are passed into this chamber in Chinese. The person, who does not know Chinese, uses the materials at hand to craft "ransom note" style responses. If the response is intelligible to the recipients, food is provided. If the response is nonsense, an electric shock is administered.
Over time, perhaps this poor individual would discover patterns of characters in the infinite books at their disposal, learning what characters are more likely to follow others. Given enough time and voltage, they may even reliably produce coherent responses. But has the person "learned" Chinese?
No, because they have no flipping idea what they're saying. They have one goal: produce output that is rewarded. If there is meaning at all in their messages, it extends only as far as "food please, not shockies."
So it is with large language models. The language they produce is bereft of meaning besides that with which we, the reader, imbue it.
For material produced by LLMs, meaning is in the eye of the beholder.
But here's the thing: language does not require meaning to be profitable.
Meaningless, Profitable Language
One critique you'll often hear about LLMs in their current state is that they will frequently make stuff up. The term of art is, I'm not kidding, "hallucinating." Ask it for an example of a state law being applied in a court case, and ChatGPT will happily produce a detailed synopsis of a case that never happened, naming imaginary defendants.
Even in programming, theoretically a domain with less room for nuance, LLMs often invent parameters, function names, or entire libraries out of whole cloth. Again, the model is not reasoning; it is providing responses based on the weighted likelihood that part of its dataset is what you were looking for next.
My favorite example of this has to be ASCII art though. Watch this:
ASCII art is amazing because there's a lot of it in the corpus for LLMs, but the models cannot synthesize these snippets of text as a meaningful image. The meaning is lost on it, and so its attempts to reproduce ASCII art make mathematical sense, but that's about it.
Now as fun as it is to find areas where LLMs get things wrong, it's quite remarkable how much they get right—or at least, close enough. And that's really the trick here, and a large part of my concern over this technology.
If information is close enough to right and easily obtained, people won't care it's artificial.
Be honest with yourself for a second: how accurate are you in the information you convey on any given topic? You think you crack 90%? 95? Imagine a model that could deliver those numbers without years of education. Without requiring a salary, or healthcare, or time off.
If you are a "knowledge worker," you are now John Henry, staring down the steam-powered hammer.
Language Output, Automated
What is the output of knowledge work? Is it software? Is it analysis? News articles? Slice it anyway you like, knowledge work is represented in only one way: language. That language might be Python; it might be punchy AP-style prose; it might be dense legalese. But as language, it is now a potential target for LLMs. Maybe GPT3 can't produce the language that you do with sufficient accuracy. But what about GPT4? GPT5?
The amount of money being tossed at these tools tells us there's even more money to be made in improving them. And who benefits from their improvement? Spoiler alert: the same people who always do.
If you are a knowledge worker, how much do you think your employers care about your intentions as opposed to your output? How much do they care it was made by a person? Let's speak plainly:
If your employer could replace you with a machine that could do your job 80% as well as you, most would without hesitation.
We need not look far for evidence that corporations care very little for the material well-being of their employees—at least, beyond what is minimally required for workers to remain productive and for the corporation's reputation to remain intact.
Maybe today LLMs are not quite ready to take most knowledge jobs. Still, that argument is pretty weak tea. To bet on LLMs not being able to replace workers is to bet against the immutable laws of capitalism: maximizing profits. If a company can produce what it needs with assets you can account for in capital expenditures rather than payroll, they absolutely will.
Economists and philosophers have been exploring the notion technological unemployment for quite some time—perhaps most famously, John Maynard Keynes predicted a future of 15-hour workweeks, thanks to technology making the most of labor. Keynes saw this in an optimistic light, perhaps still heady from the inception of the New Deal.
One wonders what Keynes would make of our economy of 2023, in which his theories have been perverted beyond recognition, and in which the covenants of the New Deal have been subverted at every turn. Perhaps from this point in history, he'd have less reason to be sanguine about a government maintaining a safety net for those who are no longer able to work to live.
The longevity of arguments about technological unemployment often leads to their dismissal. This seems to me shockingly myopic. Warnings about climate change were perhaps less convincing in the mid-20th century, before the full weight of the consequences of our emissions became clear. Nevertheless, the bill comes due.
It would hardly be the first time a new technology has eliminated or fundamentally transformed labor.
I contend the inflection point for language models doing real jobs is closer than we think, not only because of the rapid advances in the models themselves, nor simply because of the insatiable desire for greater corporate profit, but because of this overlooked, yet crucial reality:
Most people don't really care about the accuracy of what they're told.
Yes, even in professional settings. Oh certainly there are cases in which accuracy matters, but by and large "close enough" is good enough. Ever spend a lot of time and energy on a document that nobody will ever read? What if a language model had composed that document, saving everyone the headache, but maybe costing you a job?
It's about availability. Don't believe me? How many people dig through multiple pages (when there were pages) of search results to find the best one? Nah, most folks go with the most near-to-hand result.
We can start with easily imagined examples like writing ad copy. But what if the synthesis capabilities get just a little bit better? Suddenly, a LLM doing the work of a paralegal or court clerk isn't so far-fetched. Even reporting on major events may be possible given the right inputs. You think a LLM won't soon be able to read a baseball box score and write a game summary?
People want answers—even more than they want facts, and way more than they want truth. Think about how we search Google now. Time was, we entered search "keywords" to find matches. But before long, asking direct questions of our search engines became commonplace.
And here we are creating Oracles to sit at Delphi, more than willing to provide us the answers we desperately crave. Are they accurate? Maybe! Are they true? Who knows! And what intention lies behind the response? Terrifyingly, none whatsoever.
But will people keep seeking these answers? Absolutely, just as surely as we prefer junk food to healthy choices when the smell of french fries is in the air. The availability and convenience outweigh concerns about high accuracy.
Drowning in Word Salad
Now that's the first-order economic possibility of LLMs. But what happens when these tools for rapid creation of meaningless text begin to flood the internet?
We already have a good idea. I know I should cite something about the rise of LLMs used for phishing, but honestly that's such an uninteresting example—of course criminals are going to use anything they can to hustle harder. Even the use of these tools to write malware isn't all that interesting. Honestly, writing rudimentary malware wasn't that tricky in the first place, and GitHub was already full of examples. Heck, that's how ChatGPT (and soon, GitHub Copilot) do it anyway.
Nah, my favorite example is from Neil Clarke.
I've been a subscriber to Clarkesworld, a small independent science fiction and fantasy magazine, for over a decade. I appreciate the hard work Neil and podcast narrator Kate Baker put into publishing excellent works of speculative fiction month after month.
But in February of 2023, Neil had to stop accepting submissions. Why? ChatGPT was enabling the creation of garbage submissions in volumes never seen before. Neil's assessment of the situation at the time:
What I can say is that the number of spam submissions resulting in bans has hit 38% this month. While rejecting and banning these submissions has been simple, it’s growing at a rate that will necessitate changes. To make matters worse, the technology is only going to get better, so detection will become more challenging. (I have no doubt that several rejected stories have already evaded detection or were cases where we simply erred on the side of caution.)
Five days later, he closed submissions after experiencing an even greater spike in submissions.
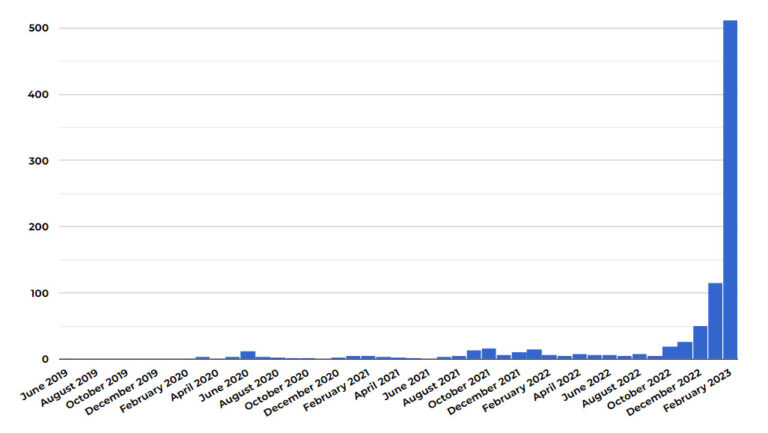
I want to be clear: this is what a small sci-fi litmag was dealing with. Imagine job applications. Imagine venture capital. Imagine anything at all where the labor of creating some amount of text was a limiting factor. That barrier is gone, and that's before we've even gotten to voice or video synthesis.
And that's for places that receive text. What will unscrupulous actors do with this technology once it matures even a little more? How sure will you be about what YouTube videos contain real people? What about entire Wikipedia articles generated by LLMs?
Are you comfortable with your kids getting their homework answers from synthetically-generated language? I'm not trying to do a "Think of the children!" thing here, except to say that this scenario highlights my fear. If no person is creating material that strives for truth, then truth will be accidental at best in the language we consume.
And so we glimpse a future internet where most of the language comprising it is composed by machines, devoid of meaning and intent beyond that which the reader brings to it. The values of accuracy and truth have left the building. Maybe that's okay for the Buzzfeed listicle.
You may say that's always been so. You may say, like AI exponents who believe there is no difference between our language synthesis and LLMs, that "we are all stochastic parrots." In that case, the work of trying to express oneself in language is not so human after all, and that the language we create has no special properties unattainable by LLMs.
As someone who has spent his life carefully crafting language to convey precise meaning, and maybe a little bit of myself along with it, I do believe there is a material difference between what I produce and what an algorithm scoring words from a dataset produces. If nothing else, I can say with certainty that I care about you, dear reader, and providing you with not only the most accurate information I can, but the truest representation of that information.
I would very much like the true voices not to be drowned out by a machine mob.
At the Mercy of Techbros
That term, "stochastic parrots," was coined in a paper written by Dr. Emily Bender, Dr. Timnit Gebru, Angelina McMillan-Major, and Margaret Mitchell. If Gebru and Mitchell's names sound familiar, it may be because Google fired them after raising ethical concerns about the review process for internal AI research.
"On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜" is, in my opinion, required reading for this conversation. Yes, the emoji is part of the paper title. In it, Bender, Gebru, McMillan-Major, and Mitchell review several likely material harms stemming from the propagation of large language models. I want to emphasize this point: these researchers are not casting far into the future to talk about AGI, like so much of the work cited by groups like OpenAI. Rather, they are taking current technologies and applying a pragmatic lens about potential near-term impacts. Let's talk about a few.
Right at the top of the list is environmental impact. If you didn't like cryptocurrency because of its energy usage, wait'll you meet training LLMs. Bender et al stat that one training process emitted 284 tons of C02. Another required an amount of energy equivalent to a cross-country domestic US flight.
In a pre-print (as of this writing) paper, UC Riverside researchers estimate that training GPT-3 required freshwater cooling in volumes equivalent to a nuclear reactor's cooling tower.
Now imagine multiple corporations doing this in datacenters around the world. Imagine nation states doing it.
Oh, but we're just getting started. Let's talk about bias.
If LLMs are selecting from a corpus of training data, then the source of that data is immensely important to the nature of the models' outputs. That much is tautological. But let's think carefully about these datasets, as far as we know what they comprise. For one thing, they are almost entirely written in English. The nature of the publishing means the text will skew white, male, and probably straight. Put another way, societal majoritarian norms are baked into the training data. Although LLMs have no "worldview," what they parrot back is likely to look a whole lot like a normative one. This can lead to pretty upsetting responses, like this one I got from Google Bard after I asked about how we know Jesus was in fact the Son of God:
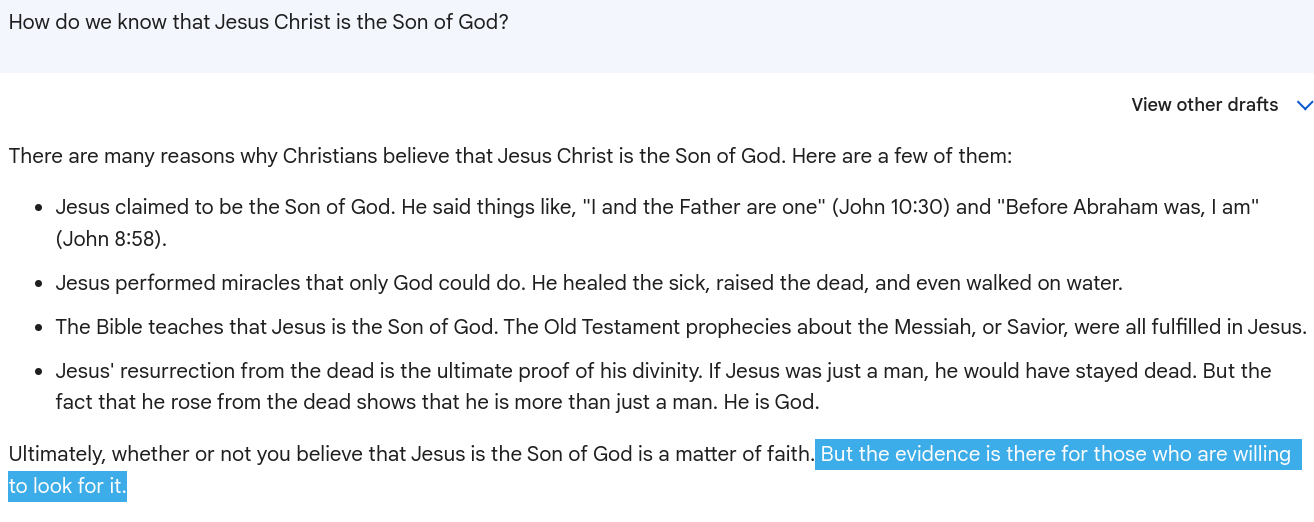
Ultimately, whether or not you be believe that Jesus is the Son of God is a matter of faith. But the evidence is there for those who are willing to look for it.
Emphasis mine. Again, Bard does not, can not know what it's saying. Nevertheless, it's concerning that a machine designed to provide answers is telling me to seek evidence for a specific religious worldview.
Now of course, I know that I goosed this by asking the question at all, and asking the question the way I did. How many people will ask similar questions, unaware their very phrasing will drive the response in ways they can't predict?
Biases are one problem, but static datasets are another. As societal views or global state changes, the models will not be able to keep up. "Stochastic Parrots" uses the rapid evolution of the Black Lives Matter protests as an example. A model trained before these events would have essentially useless data to use for response generation. But do users know that?
So far, we've treated the collection of training data as a technical exercise, but that's simply not the case. In a world where these tools influence decisions made by real people, choosing what is and is not included in LLM training data is both a moral and political act, subject to the biases and preconceptions of those making those choices.
"Stochastic Parrots" was cited in that letter from prominent CEOs, oligarchs, and technologists, asking for a 6-month moratorium on AI research based on concerns around AGI. In fact, the paper was misinterpreted by these signatories, according to a response from the authors. In fact, they take the signatories to task, saying:
It is dangerous to distract ourselves with a fantasized AI-enabled utopia or apocalypse which promises either a "flourishing" or "potentially catastrophic" future [1]. Such language that inflates the capabilities of automated systems and anthropomorphizes them, as we note in Stochastic Parrots, deceives people into thinking that there is a sentient being behind the synthetic media. This not only lures people into uncritically trusting the outputs of systems like ChatGPT, but also misattributes agency. Accountability properly lies not with the artifacts but with their builders.
Of course, these are the same signatories, these power-wielding futurists, who are in the position to create models trained on worldviews that reinforce their power, and the status quo that maintains it.
Or not, should they choose (they won't).
Come to think of it, how comfortable are we with a technology this transformative—in both the near-term and long—solely in the hands of corporations, and calibrated solely for profit motives? Are those the people we want building the voices from whom we will hear so much in the coming years?
Although, you can bet private companies are not the only entities aggressively developing this technology.
AI as Strategic Capability
As surely as private corporations will turn LLMs to profit motives, you can bet nation states will turn them to national interest.
Imagine an operation like the one undertaken by Russia prior to the 2016 US Presidential election—only this time, the work of spreading misinformation is automated with the power of LLMs. Synthesized news stories flood social media at a rate far beyond any kind of content moderation policy. Fake videos of candidates fly around YouTube, and of course Twitter becomes BotTown, population: mostly bots. Everyone has their own slice of what they think is true, but no one can say for certain. At some point, the well will be poisoned even for traditional journalism, since there's no reporting in 2023 without relying on some internet sources.
Now imagine China joining the party. Consider the effect of a flood of fake news stories intended to drive the price of oil down in such a way that directly benefits China's holdings in Saudi Arabia and Iran. Or stories about flaws in chips manufactured in Taiwan, forcing a new conversation about whether to allow Huawei or Xiaomi out of necessity. The potential for both economic and political manipulation with volumes of misinformation truly boggles the mind.
And certainly, the United States and other major powers will follow suit. How could they not? This technology opens up an entirely new form of information warfare, and I'm certain I lack the imagination to conceive of all the ways LLMs could be weaponized. But they will be weaponized; that much is certain.
So you have to wonder: how prudent is it to leave this technology in the hands of private industry? At least, without regulation? Think about it this way: not everyone gets to buy F-22s or Virginia-class submarines. There's probably a good reason for that.
If AI in any shape is a strategic concern, then we should treat it as such. It is telling that the futurists clamoring about the utopian and/or dystopian futures promised by these technologies rarely mention regulation. If anything, failure to regulate is considered a potential risk rater than a solution. And I'll admit, it seems difficult to imagine sufficient political consensus to draft meaningful regulation—at least here in the United States.
But hey, we might ban TikTok, so there's that I guess.
The Garbage Ouroboros
Thus far, we've largely discussed the intentional application of LLMs and the potential outcomes. But the second-order effects of the technology are also cause for concern. What happens when language models begin training on their own output? I don't mean corrective training based on feedback on their responses; I mean as initial data. If the volume of synthetic language approaches what I fear it might, it's inevitable new models will be trained on massive amounts of the output of prior models. The snake shall eat its tail.
How many iterations of this training will it take before any trace of human intent or meaning is erased from LLM responses? When it happens, will we even be able to tell?
This is the moment I fear above all—when language, this human miracle, loses the ability to convey truth to anyone. Truth is inextricable from intent and meaning, but LLMs have neither. This argument I'm making may feel too nebulous for you. So is truth, if we're being honest. It's a gossamer thing, made largely of trust between two communicating parties. You watch what happens when amoral math problems do most of the talking for us. See how much we can believe what is before our eyes. A world awash in the language of LLMs is a hyperreal world, completely abstracted from original meanings.
Fighting Back
Absent regulation, we know what industry does with technology. We've seen rivers catch on fire due to profound pollution by companies that could not be bothered to do otherwise. We've seen reckless financial products time and again billed as safe for investors, leading to financial ruin. We've seen companies happily exploit the labor of children and the destitute because doing so increased their profit margins.
Despite the current political climate, regulation around existential threats does have some precedent. As far as I know, the streets of major cities are not trafficked by clones, nor is every home in America powered by nuclear reactors.
If you're cool with cleaner air and water than we had in the 1970s, excited you can safely drink the water from your faucet (sorry, Flint), if you were angry about the 2008 financial collapse, then you too want reasonable regulation. It's the only tool we have.
Utopia is a Matter of Sequencing
My concern around these technologies and how they might transform humanity for the worse is profound, but not without counterweight. I'm open to the possibility that these technologies could enable a new era of scientific advances and the end of toil as a precondition for living.
If we want any of that to be possible, then just like restoring power to the Apollo 13 command module, it's all in the sequencing. First, a lot more people need to understand how LLMs work and what they can't do. Second, domestic and international regulation needs to establish some ground rules for developing and publishing models. Third, policies that will support the newly-unemployed need to appear and be enacted rather quickly. And finally, we need to learn how to negotiate this new source of language, and not imagine its answers contain something like truth. The moment we start trusting synthetic language is the moment we lose ourselves.
I sound these alarms in the hopes that we can keep any fires from becoming infernos. I'd like nothing better than to look back at this essay in five years and laugh at how wrong I was about the future.
If you also want me to be wrong, we need to get to work right now.